이런 lock에도 여러가지 종류가 있고, 명시적으로 사용되는 경우/묵시적으로 사용되는 경우가 있는데, 간단하게 알아보자
시작하기 전 3줄요약
Lock이 미치는 범위를 level로 나눈다
Lock 모드별로 충돌하는 관계가 존재한다
Lock은 트랜잭션 종료 시 혹은 롤백시에 풀린다.
lock이 미치는 범위를 Level로 나누는데, Table-Level Lock, Row-Level Lock, Page-Level Lock, Database-Level Lock 까지 다양하게 존재한다.
Table-Level Lock
Table Level Lock은 테이블 수준에 락을 거는 방법이다.
만약 테이블 내에 100개의 로우가 있다고 하면 하나의 로우에 접근하는 동안 나머지 99개의 로우에 접근 할 수 없기 때문에, 다중 사용자 환경에서는 사용하지 않는 편이 좋다.
(보통 테이블 전체 로우의 변경이 있는 DDL 구문과 함께 사용됨. (ex) TRUNCATE, ALTER))
이런 Table Level Lock은 LOCK 명령어를 이용해서 명시적으로 걸어줄 수도 있지만, 우리가 특정 쿼리문을 사용할 때 마다 묵시적으로 걸리게 된다. 어느 상황에 어느 락이 걸리는지는 해당 문서를 보면 알 수 있다.
Row-Level Lock
Row-Level Lock은 row 수준에 락을 거는 방법이다.
SELECT ~ FOR SHARE과 같은 DML 구문과 함께 가장 자주 사용되는 Lock이다.
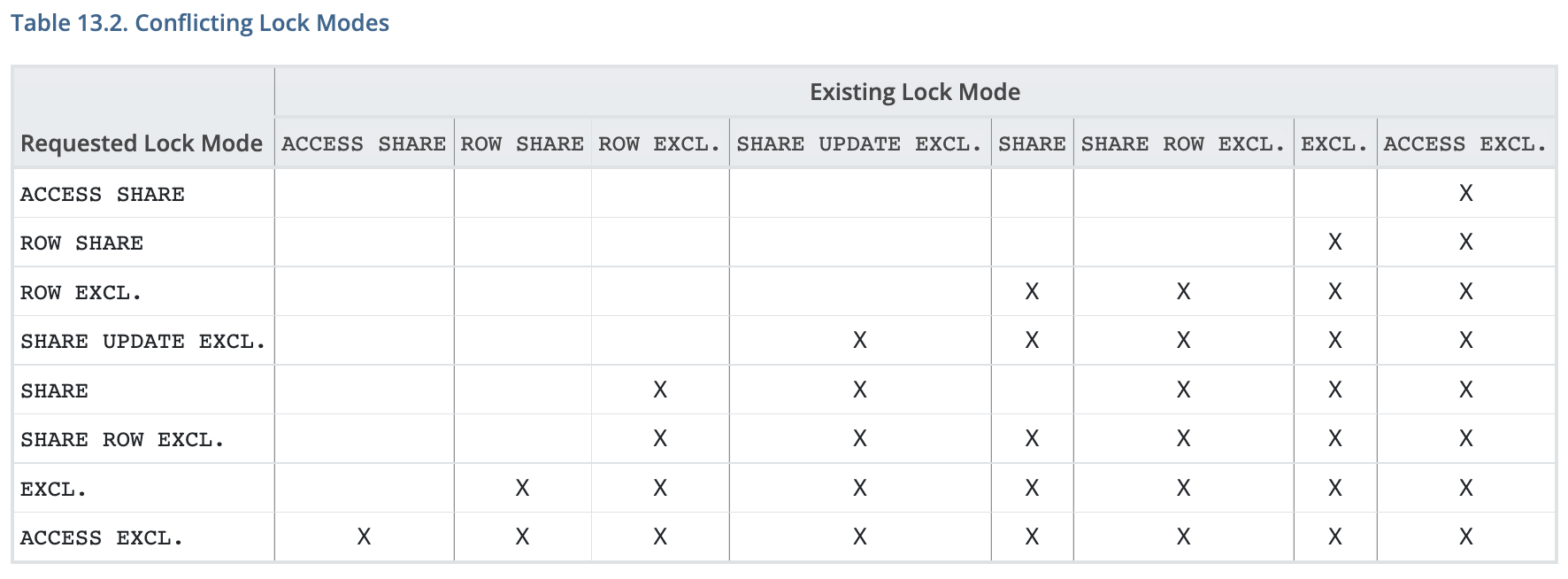
만약 이런 Lock의 종류가 하나밖에 없다면, 여러 종류의 트랜잭션에서 lock을 알맞게 사용하기 어려워지는데, 이런 상황을 처리하기 위해 Lock에는 Lock모드라는 것이 존재한다.
Lock 모드?
Lock 모드 별로 서로 충돌하는 Lock 모드가 있으며, 충돌한다면 해당 리소스(table, row)에 동시에 접근할 수 없게 된다다.
ACCESS SHARE락은 ACCESS EXCLUSIVE 락과 충돌한다,
ROW SHARE락은 EXCLUSIVE, ACCESS EXCLUSIVE 락과 충돌한다
Table-Level Lock에는ACCESS SHARE, ROW SHARE 등, Row-Level Lock에는 FOR UPDATE, FOR KEY SHARE 등 여러가지 Lock 모드가 존재한다. 이런 모드들의 이름은 일반적으로 사용되는 경우를 나타내지만, 모드마다 기능적으로 다른 점은 없다.
1. Bastion VM pgcopydb 설치 및 연결 테스트
2. Source DB유저에게 모든 sequence 권한 부여
3. Target DB유저에게 임시로 superuser 권한 부여
4. DB 동기화
5. 복제 상황 모니터링
6. 복제 지연 최소화 대기 및 데이터 검증
7. api, worker, cron pod 제거
8. 복제 지연 없음 확인
9. pgcopydb 프로세스 종료
10. replication slot, origin 삭제
11. target DB유저 superuser 권한 제거
12. api, worker, cron 재배포
순서대로 차근차근 진행해보자
1. Bastion VM pgcopydb 설치 및 연결 테스트
sudo apt update
sudo apt install pgcopydb
mkdir -p pgcopydb-migration
cd pgcopydb-migration
export PGCOPYDB_SOURCE_PGURI="postgres://source-db:thisispassword@127.0.0.1:5432/source-db"export PGCOPYDB_TARGET_PGURI="postgres://target-db:thisispassword@127.0.0.1:5433/target-db"
pgcopydb ping --source"$PGCOPYDB_SOURCE_PGURI" --target "$PGCOPYDB_TARGET_PGURI"# 기대 출력## INFO Successfully could connect to source database## INFO Successfully could connect to target database
2. Source DB유저에게 모든 sequence 권한 부여
-- source-db 유저에게 모든 sequence 권한 부여GRANTSELECT, USAGE ONALL SEQUENCES IN SCHEMA public TO "source-db";
3. Target DB유저에게 임시로 superuser 권한 부여
-- 임시로 superuser 권한 부여ALTERUSER "target-db" WITH SUPERUSER;
4. DB 동기화
nohuppgcopydb clone --follow \
--source "$PGCOPYDB_SOURCE_PGURI" \
--target "$PGCOPYDB_TARGET_PGURI" \
--no-owner \
--no-acl \
--table-jobs 1 \
--index-jobs 1 \
--verbose \
--dir . \
> ./pgcopydb-migration.log 2>&1 &
# 프로세스 ID 저장echo$! > ./pgcopydb-migration.pid
# 실시간 로그 확인tail-f ./pgcopydb-migration.log
# 진행 상황 확인./replication_monitoring.sh
6. 복제 지연 최소화 대기 및 데이터 검증
복제지연 확인
SELECT
slot_name,
active,
pg_size_pretty(pg_wal_lsn_diff(pg_current_wal_lsn(), confirmed_flush_lsn)) as lag_size,
pg_wal_lsn_diff(pg_current_wal_lsn(), confirmed_flush_lsn) as lag_bytes
FROM pg_replication_slots
WHERE slot_name ='pgcopydb';
-- Result --
slot_name | active | lag_size | lag_bytes
-----------+--------+----------+-----------
pgcopydb | t |541 kB |553920
(1row)
데이터 일관성 검증
pgcopydb compare schema --verbose
pgcopydb compare data --verbose
약 541KB 만큼의 복제 지연이 있다는 의미이다.
# 데이터 정합성 확인
pgcopydb compare data
# Output
16:11:44.270162208 INFO Running pgcopydb version 0.17-1.pgdg22.04+1from "/usr/bin/pgcopydb"
16:11:44.357162208 INFO Using work dir "/tmp/pgcopydb"
16:11:44.358162208 INFO SOURCE: Connecting to "postgres://target-db@127.0.0.1:5432/target-db?keepalives=1&keepalives_idle=10&keepalives_interval=10&keepalives_count=60"
16:11:44.361162208 INFO Re-using catalog caches
16:11:44.365162208 INFO Starting 4table compare processes
Table Name |!| Source Checksum | Target Checksum
-------------------------------+---+--------------------------------------+-------------------------------------
public.user ||9136aaf4-0f32-cd2b-850f-49270ff7c03 |9136aaf4-0f32-cd2b-850f-49270ff7c03
그러다 문득, "공약만 보고 비교하여 나에게 맞는 후보자를 찾는 사이트가 있으면 어떨까?" 생각이 들었다.
개발 과정
1. Project Rule 설정
claude 프로젝트를 만들고 간단한 Rule를 작성했다.
혹시나 큰일나면 안되니 선거법을 찾아보며 만들었다.
1. 정치적 중립성 유지
- 특정 후보나 정당을 편향되게 지지하거나 비판하지 않기
- 개인적 정치 성향이나 선호도 표현 금지
2. 사실 정확성 최우선
- Github Repository에 명시된 중앙선관위 등록 공약만 사용
3. 선거법 준수
- 선거 관련 법령 위반 요소 철저히 배제
- 개인정보 수집이나 여론조작 요소 금지
4. 데이터 처리
- 사용자 개인정보 수집 금지
- 클라이언트 사이드에서만 동작
- 결과 추적이나 분석 데이터 저장 금지
5. 면책 조항
- 교육 목적임을 명시
- 실제 투표 시 종합적 고려 권고
2. 데이터 사전 준비
Brave Search 등의 MCP가 존재하였지만, 정보의 형평성을 맞추기 위해 크롤링은 하지 않았다.